09-排序1 排序(冒泡、插入、希尔)
给定N个(长整型范围内的)整数,要求输出从小到大排序后的结果。
本题旨在测试各种不同的排序算法在各种数据情况下的表现。各组测试数据特点如下:
数据1:只有1个元素;
数据2:11个不相同的整数,测试基本正确性;
数据3:103个随机整数;
数据4:104个随机整数;
数据5:105个随机整数;
数据6:105个顺序整数;
数据7:105个逆序整数;
数据8:105个基本有序的整数;
数据9:105个随机正整数,每个数字不超过1000。
输入格式:
输入第一行给出正整数N(≤105),随后一行给出N个(长整型范围内的)整数,其间以空格分隔。
输出格式:
在一行中输出从小到大排序后的结果,数字间以1个空格分隔,行末不得有多余空格。
输入样例:
1
2
3
| 11
4 981 10 -17 0 -20 29 50 8 43 -5
//结尾无空行
|
输出样例:
1
2
| -20 -17 -5 0 4 8 10 29 43 50 981
//结尾无空行
|
冒泡排序
中心思想
多次遍历数组,如果相邻的数字左边比右边大就交换,一趟遍历完后最后一位是最大的数,第二趟遍历后,次大的在倒二;
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| #include<stdlib.h>
#include<stdio.h>
void Bubble_sort(int *Data,int N);
void swap(int *A,int *B);
int main()
{
int i,N,*Data;
scanf("%d\n",&N);
Data = (int*)malloc(N*sizeof(int));
for(i = 0;i < N;i++)
scanf("%d ",&Data[i]);
Bubble_sort(Data,N);
for(i = 0;i < N-1; i++)
printf("%d ",Data[i]);
printf("%d\n",Data[N-1]);
}
void Bubble_sort(int *Data,int N)
{
int i,j,flag;
for(i = N-1;i >= 0;i--)
{
flag = 1;
for(j = 0;j < i;j++)
{
if(Data[j] > Data[j+1])
{
swap(&Data[j],&Data[j+1]);
flag = 0;
}
}
if(flag)
break;
}
}
void swap(int *A,int *B)
{
int *tmp;
tmp = *A;
*A = *B;
*B = tmp;
}
|
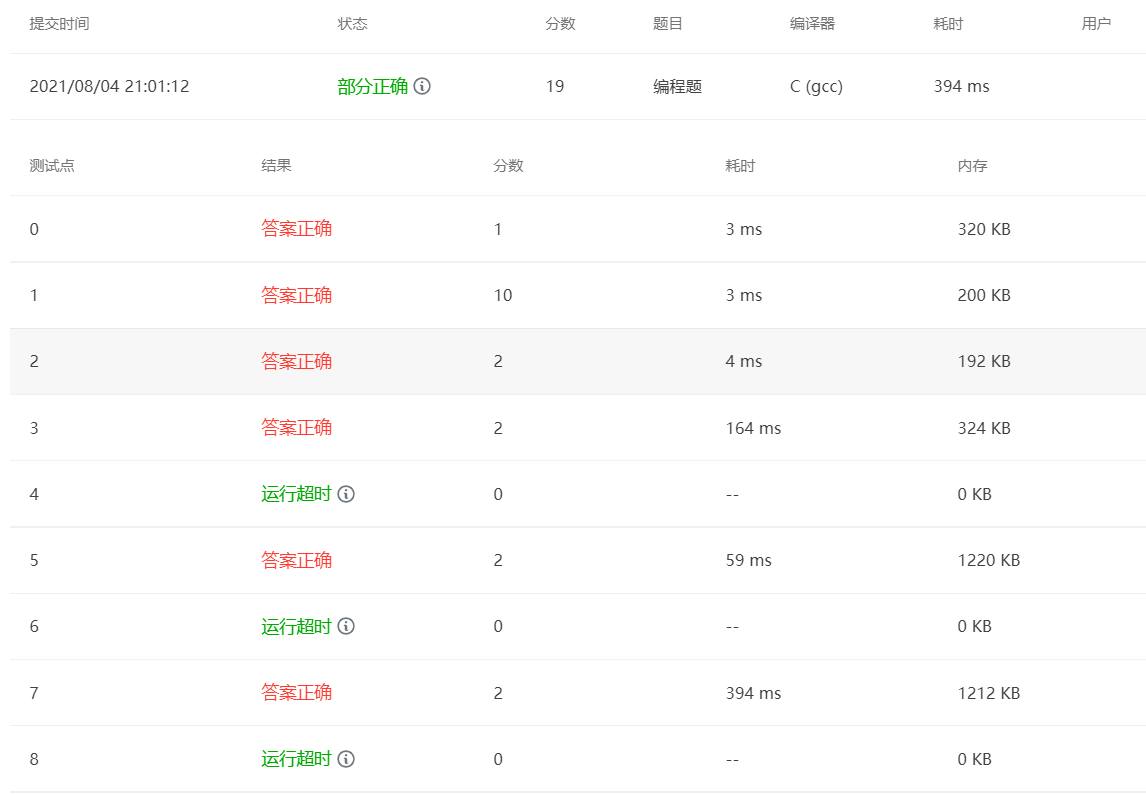
测试结果
可以看到数据量才涨到103的时候冒泡排序的效率就已经比较差了,等数据量更大了之后如果不是输入已经有序都是超时的

小结
- 小结
最坏时间复杂度是O(N2),如果数组基本有序,那么经过若干趟排序之后数组就可能是有序的,所以可能复杂度是O(N),所以通过了测试点7
评价:交换排序,简单排序,最坏时间复杂度是O(N2),在数组基本有序的情况下时间复杂度可能是O(N)。空间复杂度O(1)。
插入排序
中心思想:
就像打牌时候整理手牌,一张张的摸牌,每拿入一张牌都插入到手牌中合适的位置,保证每次插入后都是有序的
可以做的一点优化是用移位来代替交换;
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| #include<stdlib.h>
#include<stdio.h>
void Insersion_sort(int Data[],int N);
int main()
{
int i,N,*Data;
scanf("%d\n",&N);
Data = (int*)malloc(N*sizeof(int));
for(i = 0;i < N;i++)
scanf("%d ",&Data[i]);
Insersion_sort(Data,N);
for(i = 0;i < N-1; i++)
printf("%d ",Data[i]);
printf("%d\n",Data[N-1]);
}
void Insersion_sort(int *Data,int N)
{
int i,j,tmp;
for(i = 1; i < N;i++)
{
tmp = Data[i];
for(j = i;j > 0 && tmp < Data[j-1];j--)
Data[j] = Data[j-1];
Data[j] = tmp;
}
}
|
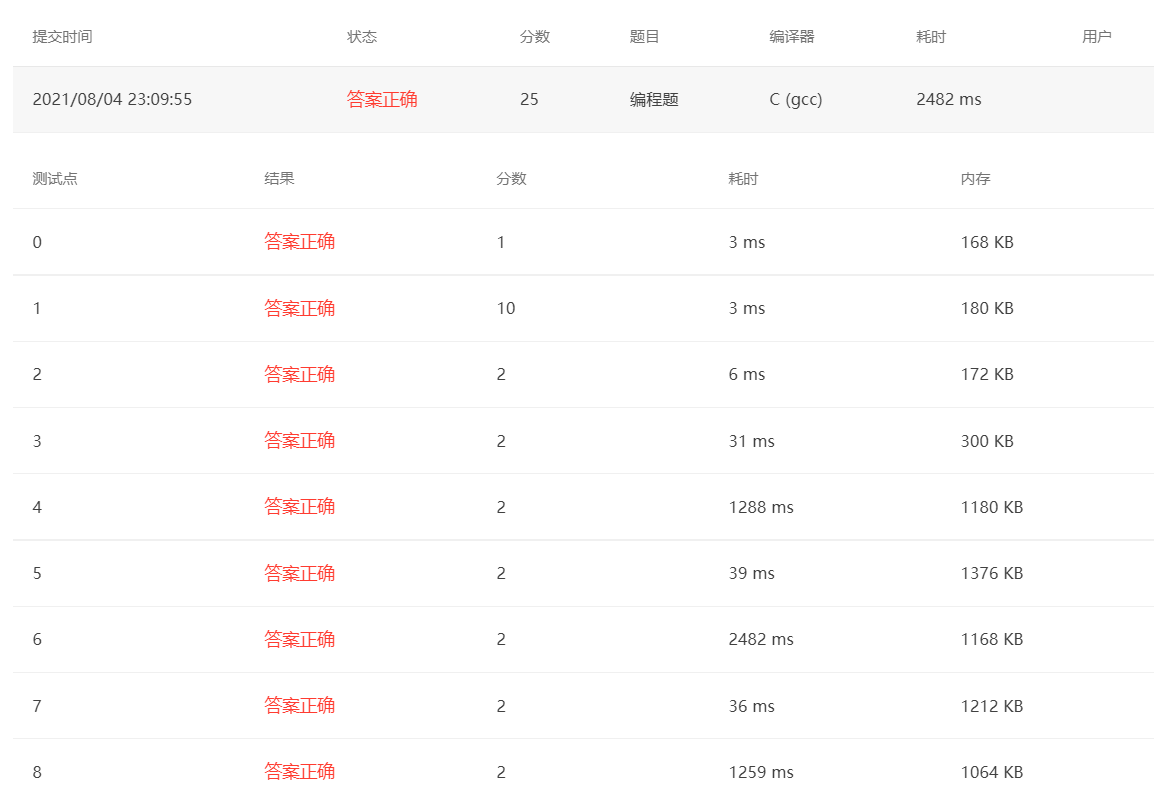
测试结果
可以看到插入排序的效果貌似略好于冒泡排序,因为它的稳定性比较好,比较的次数大概率是小于冒泡排序的
可以看出来插入排序虽然全部测试点都通过了,但是有几个测试点的数据依然比较慢,但是插入排序的测试结果整体是好于冒泡的;
插入排序的空间复杂度为O(1),插入排序的时间复杂度最坏是O(N2),是所有数据都处于逆序状态时才会遇到的情况,绝大多数情况下不会遇到,而在数组基本有序的情况下,插入排序甚至都不用移动几次就能够完成排序,所以时间复杂度可能直接降为O(N);
插入和冒泡需要完成的交换次数都是相当的,这是由于插入和冒泡每次都只交换相邻的两个元素,这使得他们每次交换都只能消去一个逆序对,由此,为了使每次交换都消除更多的逆序对便产生了对插入排序优化后的希尔排序
希尔排序
与插入排序类似,但是每次比较的不是相邻的数,而是距离为某个值的两个元素。要定义一个间隔序列: 从大到小,最后是1
如Sedgewick序列:
int Sedgewick[] = {929, 505, 209, 109, 41, 19, 5, 1, 0};
这个序列中的元素一般要是互质的,这样希尔排序性能才会并较好。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
void Shell_sort(int *Data,int N)
{
int i,j,tmp,D;
for(D = N/2;D > 0;D = D/2)
{
for(i = D; i < N;i++)
{
tmp = Data[i];
for(j = i;j >= D && tmp < Data[j-D];j-=D)
Data[j] = Data[j-D];
Data[j] = tmp;
}
}
}
void Shell_sort(int *Data,int N)
{
int Si, D, P, i,j,tmp;
int Sedgewick[] = {929, 505, 209, 109, 41, 19, 5, 1, 0};
for ( Si=0; Sedgewick[Si]>=N; Si++ );
for ( D=Sedgewick[Si]; D>0; D=Sedgewick[++Si] )
{
for(i = D; i < N;i++)
{
tmp = Data[i];
for(j = i;j >= D && tmp < Data[j-D];j-=D)
Data[j] = Data[j-D];
Data[j] = tmp;
}
}
}
|
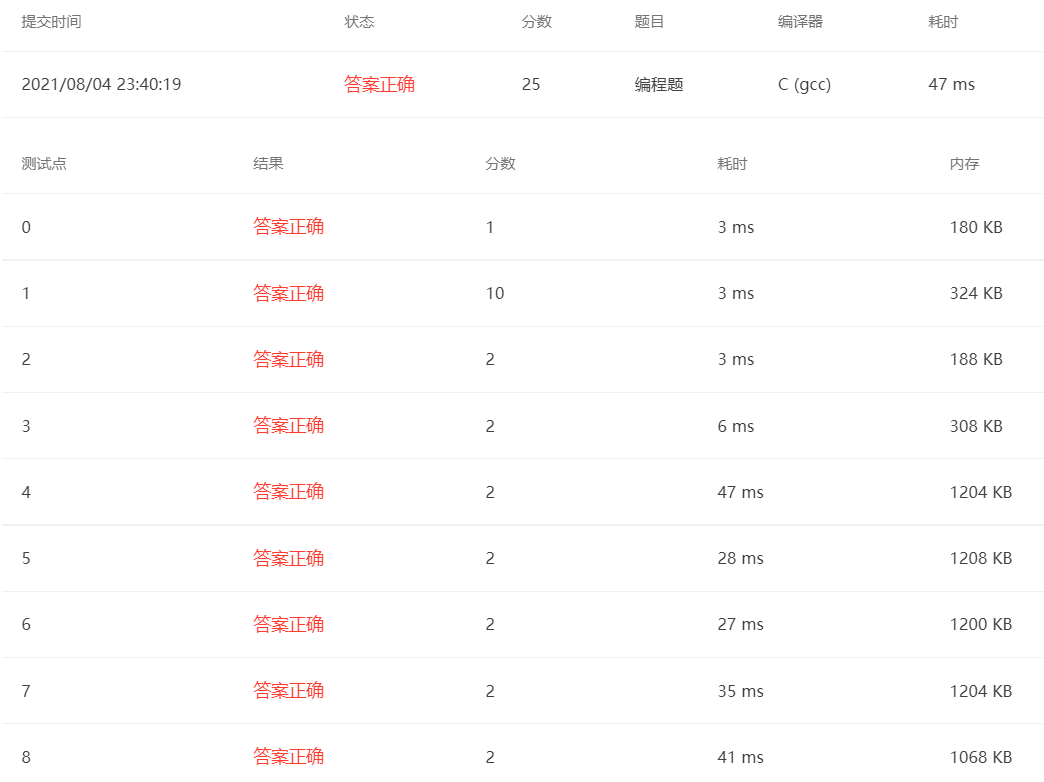
测试结果
从测试结果来看,希尔排序相对于插入排序已经快了很多,说明相对于插入排序已经优化了很多,但是希尔排序需要它的序列选取比较好才会有比较好的效果,目前人们一般认为对于Sedgewick增量序列:9×4i−9×2i或4i−3×2i+1的时间复杂度为Targ=O(N7/6),Tworst=O(4/3)
后记
今日体重,82.95kg,测量于晚饭后,早上刚起床时候还是81.9kg,感觉很不真实,就没有把欺骗自己的体重放出来
参考文章
排序算法-09-排序1 排序 (25分)-第一部分